Liam Lambert
1 februar 2025
Valg af en kompleks attribut eller ternært forhold i en ERD til et jobrekrutteringssystem
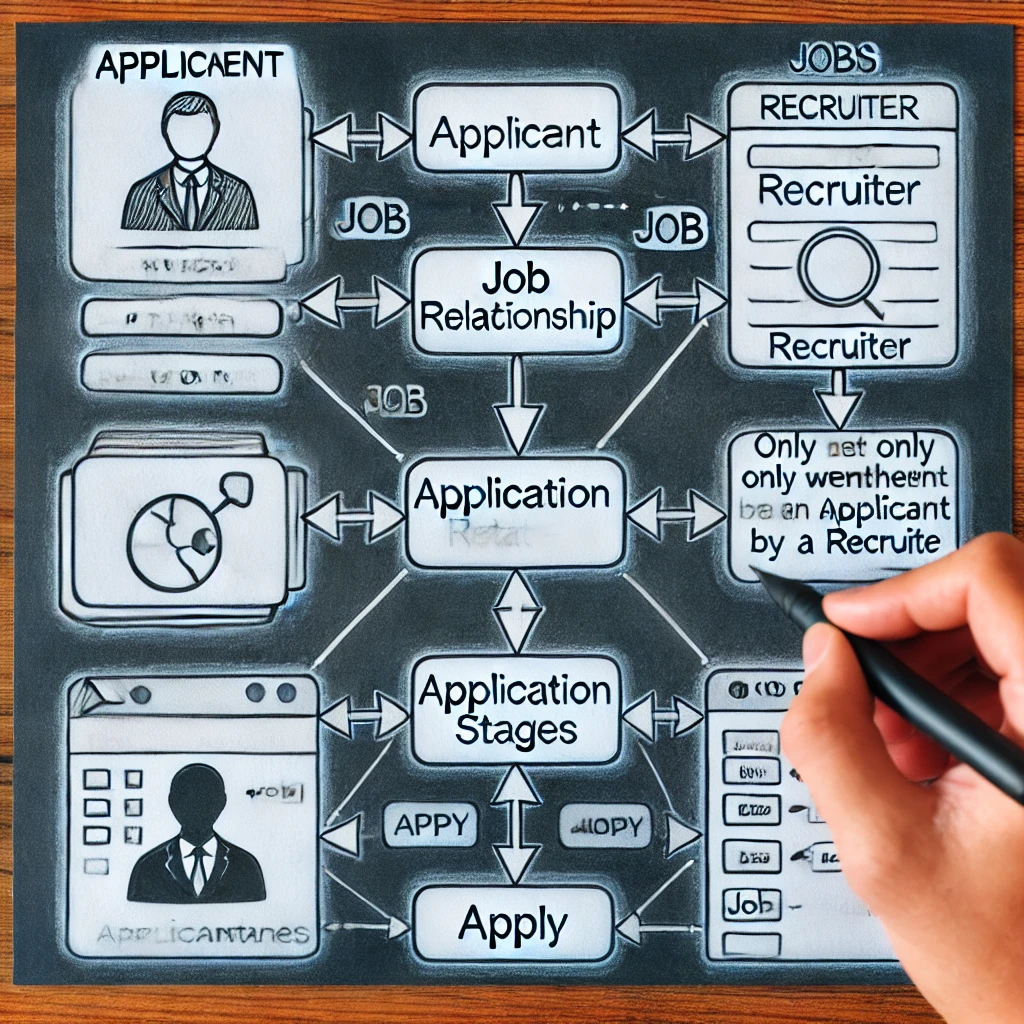
Design af et organiseret og effektivt Jobrekrutteringssystem kræver en forståelse af, hvordan man modellerer anvende -forbindelse i en ERD. Hvorvidt man skal repræsentere ApplicationStages som en kompliceret attribut eller som et svagt objekt er et afgørende valg. Metoden efterligner nærmere faktiske ansættelsesprocedurer ved at garantere, at applikationstrin kun vises efter shortlisting. At gøre den korrekte designbeslutning forbedrer databasehastigheden, mens du garanterer skalerbarhed og forespørgsel enkelhed. Ved at øge datakvaliteten og fremskynde kandidatsporing hjælper denne metodiske teknik både rekrutterere og kandidater.