Liam Lambert
1 Februar 2025
Auswählen eines komplexen Attributs oder einer ternären Beziehung in einem ERD für ein Rekrutierungssystem für Jobs
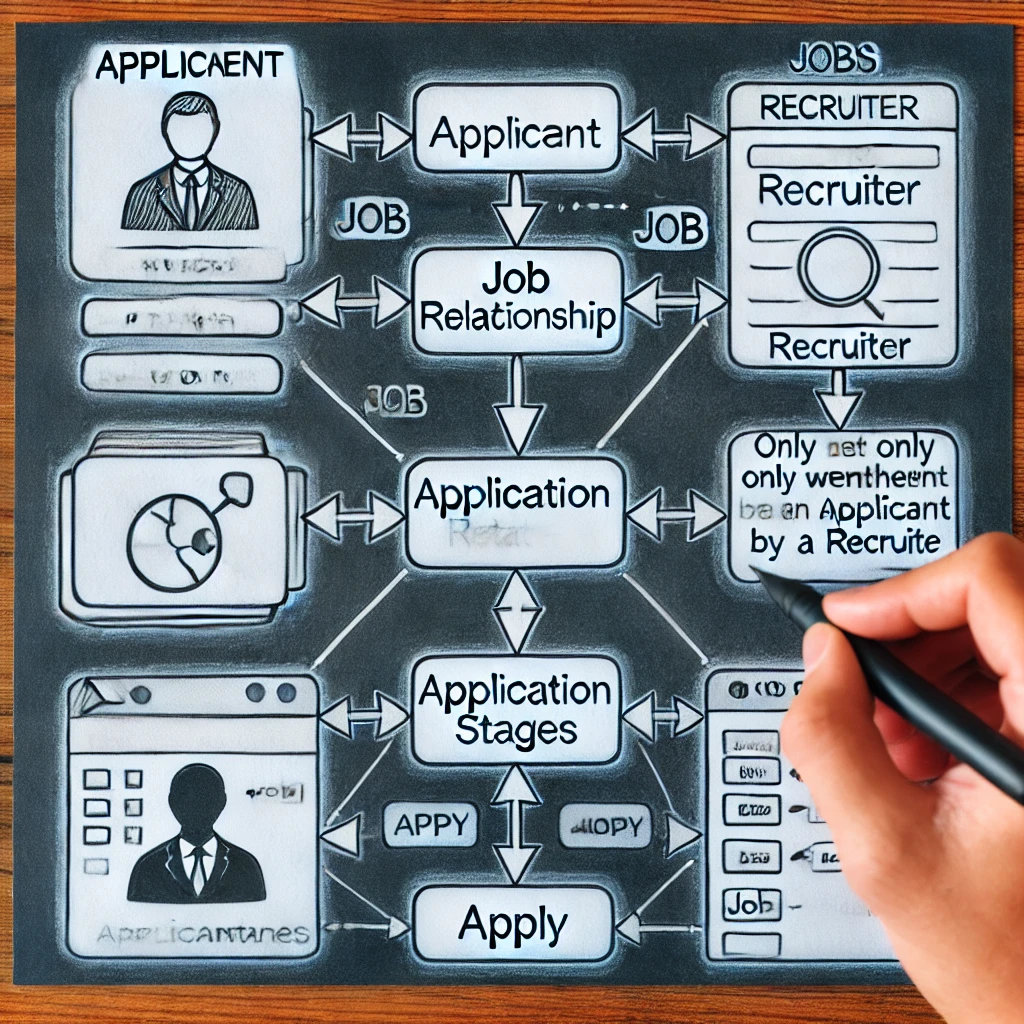
Das Entwerfen eines organisierten und effektiven -Ag -Rekrutierungssystems erfordert ein Verständnis dafür, wie die -Anwendung in einem ERD anwenden. Ob ApplicationStages als kompliziertes Attribut oder als schwaches Objekt darstellt, ist eine entscheidende Wahl. Die Methode ahmt die tatsächlichen Einstellungsverfahren besser nach, indem sie garantieren, dass die Anwendungsphasen nach der Auswahlliste nur angezeigt werden. Die korrekte Designentscheidung verbessert die Datenbankgeschwindigkeit und garantiert gleichzeitig Skalierbarkeit und Einfachheit der Abfragen. Durch die Erhöhung der Datenqualität und die Beschleunigung der Kandidatenverfolgung hilft diese methodische Technik sowohl Personalvermittlern als auch Kandidaten.