Liam Lambert
1 février 2025
Sélection d'un attribut complexe ou d'une relation ternaire dans un ERD pour un système de recrutement d'emploi
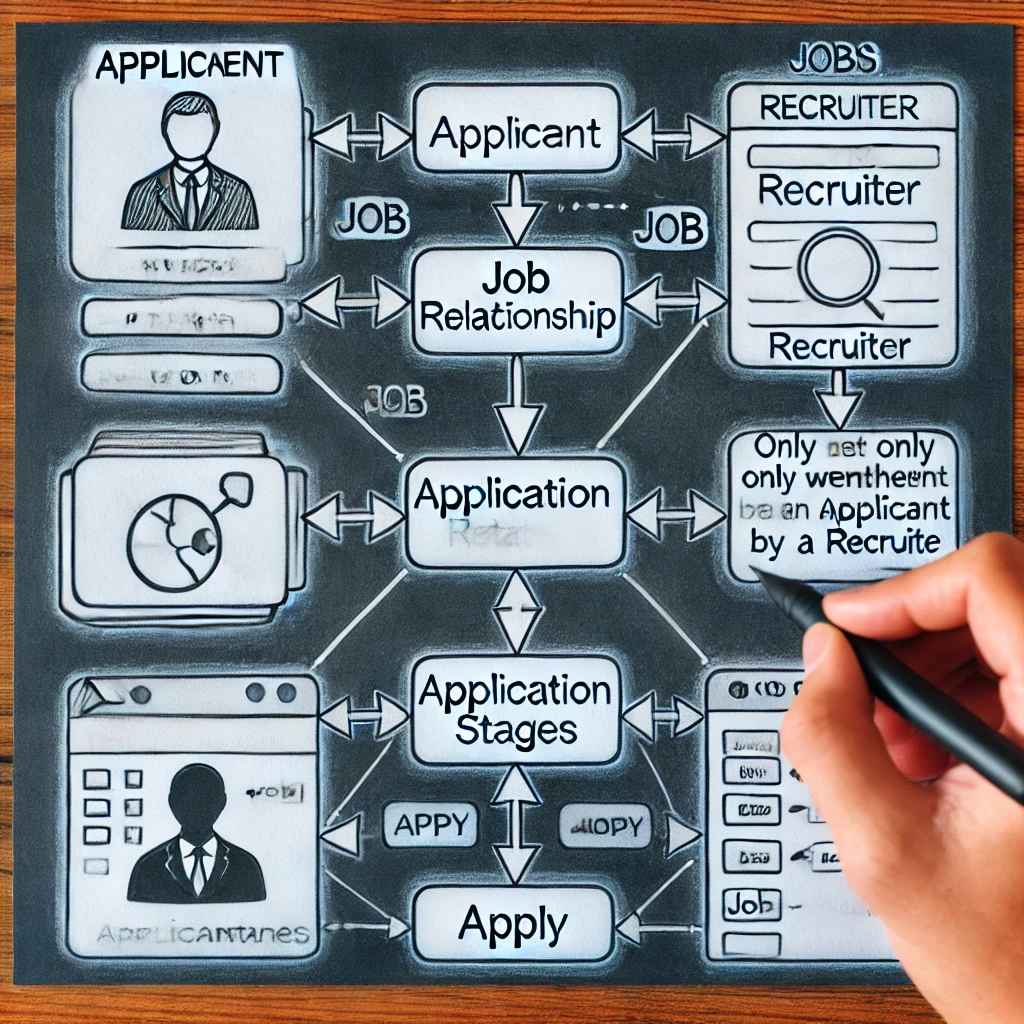
La conception d'un système de recrutement d'emploi organisé et efficace nécessite une compréhension de la façon de modéliser la connexion appliquer dans un ERD. Que ce soit pour représenter les étages d'applications en tant qu'attribut compliqué ou en tant qu'objet faible est un choix crucial. La méthode imite plus étroitement les procédures d'embauche réelles en garantissant que les étapes d'application ne s'affichent qu'après la présélection. Prendre la bonne décision de conception améliore la vitesse de la base de données tout en garantissant l'évolutivité et la simplicité de la requête. En augmentant la qualité des données et en accélérant le suivi des candidats, cette technique méthodique aide les recruteurs et les candidats.