Liam Lambert
1 febbraio 2025
Selezione di un attributo complesso o una relazione ternaria in un ERD per un sistema di assunzione di lavoro
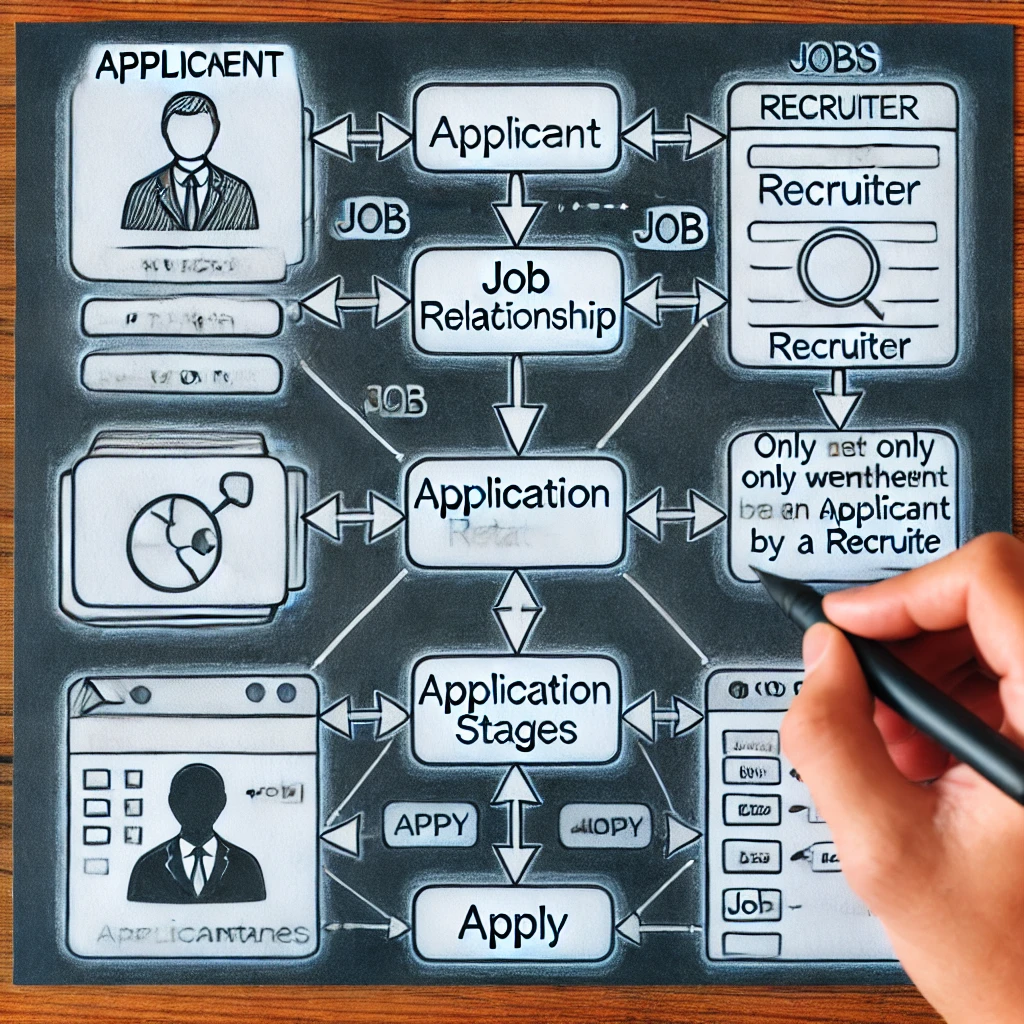
La progettazione di un sistema di reclutamento organizzato ed efficace richiede come modellare la connessione Applica in un ERD. Se rappresentare ApplicationStages come attributo complicato o come oggetto debole è una scelta cruciale. Il metodo imita più da vicino le procedure di assunzione realizzando che le fasi dell'applicazione si abbiano solo seguendo la selezione. Prendere la corretta decisione di progettazione migliora la velocità del database garantendo la scalabilità e la semplicità delle query. Aumentando la qualità dei dati e accelerando il monitoraggio dei candidati, questa tecnica metodica aiuta sia i reclutatori che i candidati.