Liam Lambert
1 2月 2025
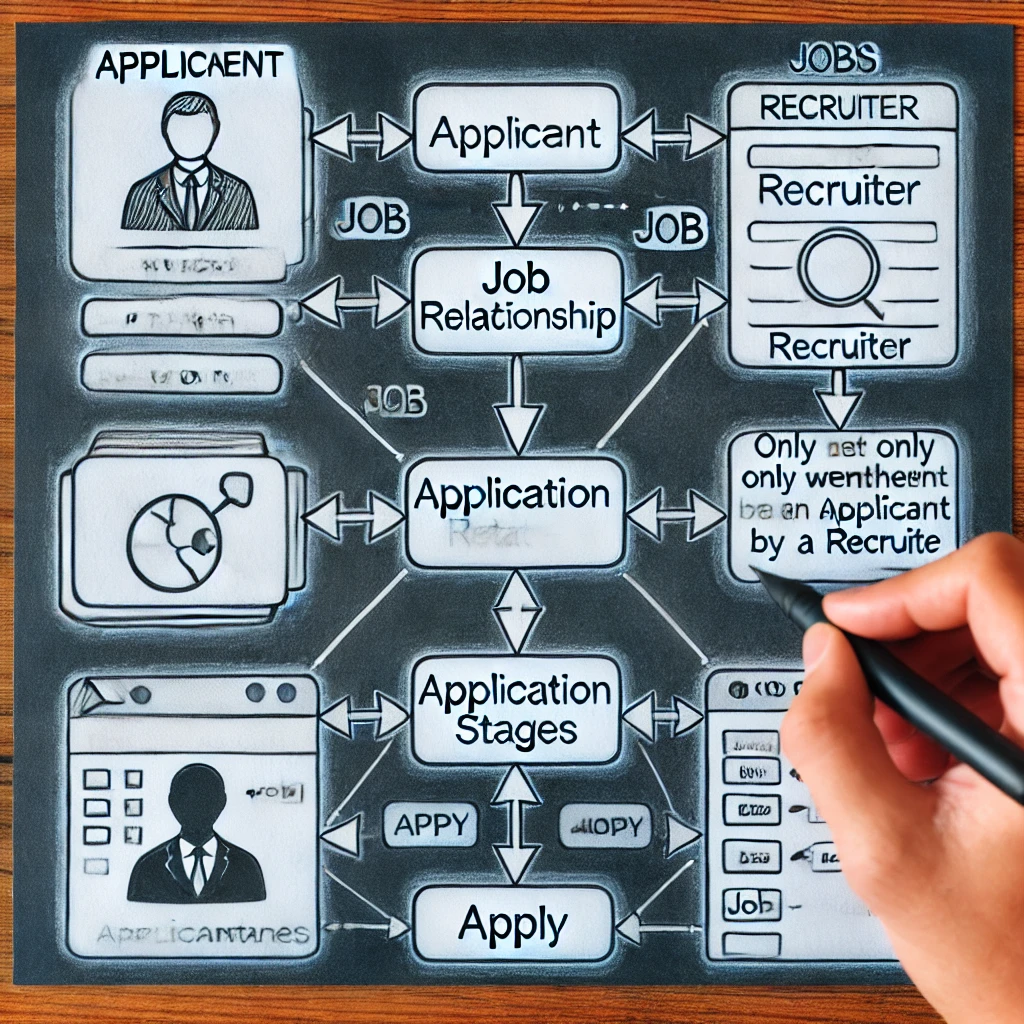
雇用採用システムのためにERDで複雑な属性または3成分関係を選択する
組織化された効果的なジョブリクルートシステムを設計するには、には、適用接続をERDでモデル化する方法を理解する必要があります。 アプリケーションステージを複雑な属性として表すか、弱いオブジェクトとして表すかは重要な選択です。この方法は、アプリケーションの段階が最終選考後にのみ表示されることを保証することにより、実際の雇用手順をより密接に模倣します。正しい設計決定を下すと、スケーラビリティとクエリのシンプルさを保証しながら、データベースの速度が向上します。データの品質を高め、候補者の追跡を促進することにより、この系統的な手法は、採用担当者と候補者の両方に役立ちます。 🚀