Liam Lambert
1 2월 2025
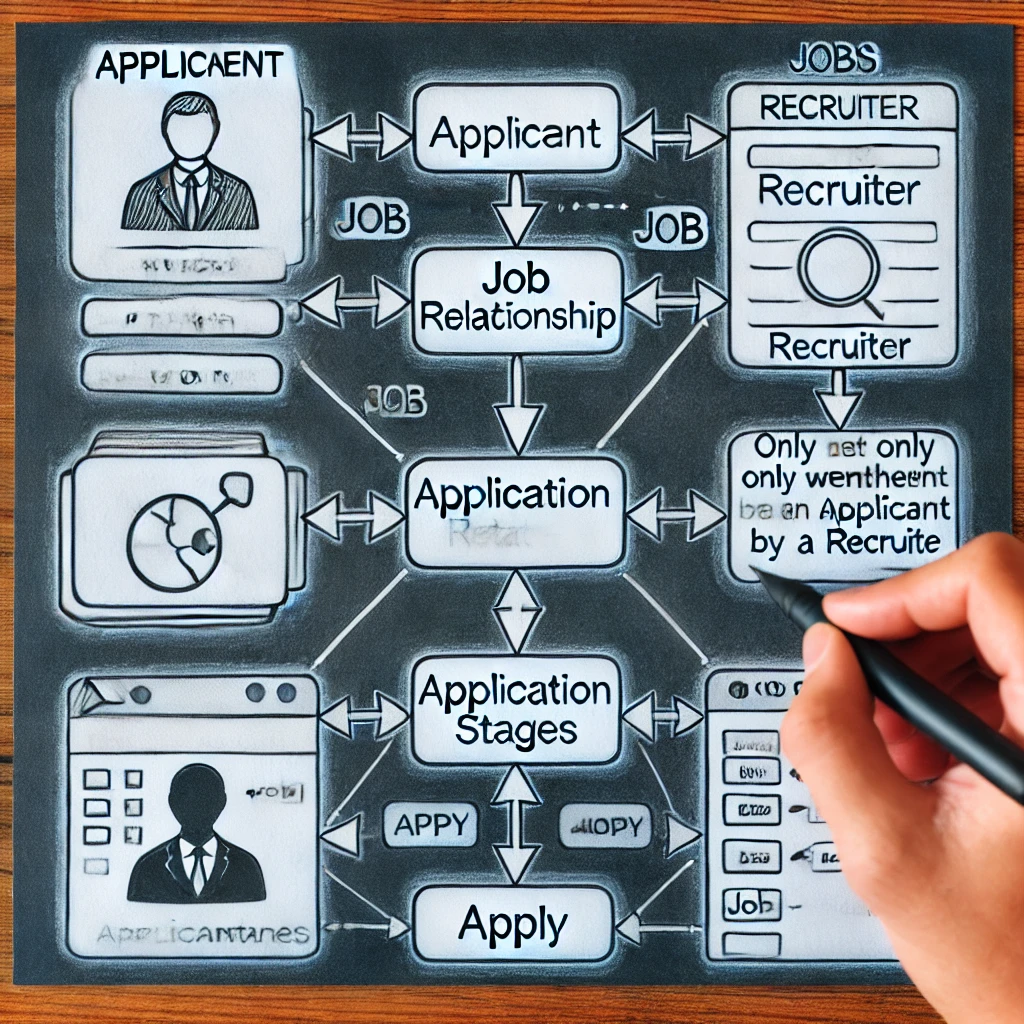
작업 모집 시스템에 대한 ERD에서 복잡한 속성 또는 3 차 관계 선택
조직적이고 효과적인 작업 모집 시스템을 설계하려면 적용 연결을 모델링하는 방법에 대한 이해가 필요합니다. ApplicationStages 를 복잡한 속성으로 또는 약한 물체로 표현하는지 여부는 중요한 선택입니다. 이 방법은 응용 프로그램 단계가 후보자 후에 만 표시되도록 보장함으로써 실제 채용 절차를 더 밀접하게 모방합니다. 올바른 설계 결정을 내리면 데이터베이스 속도가 향상되고 확장 성 및 쿼리 단순성을 보장합니다. 데이터 품질을 높이고 후보 추적을 신속하게 함으로써이 체계적인 기술은 채용 담당자와 후보자 모두에게 도움이됩니다.