Liam Lambert
1 februari 2025
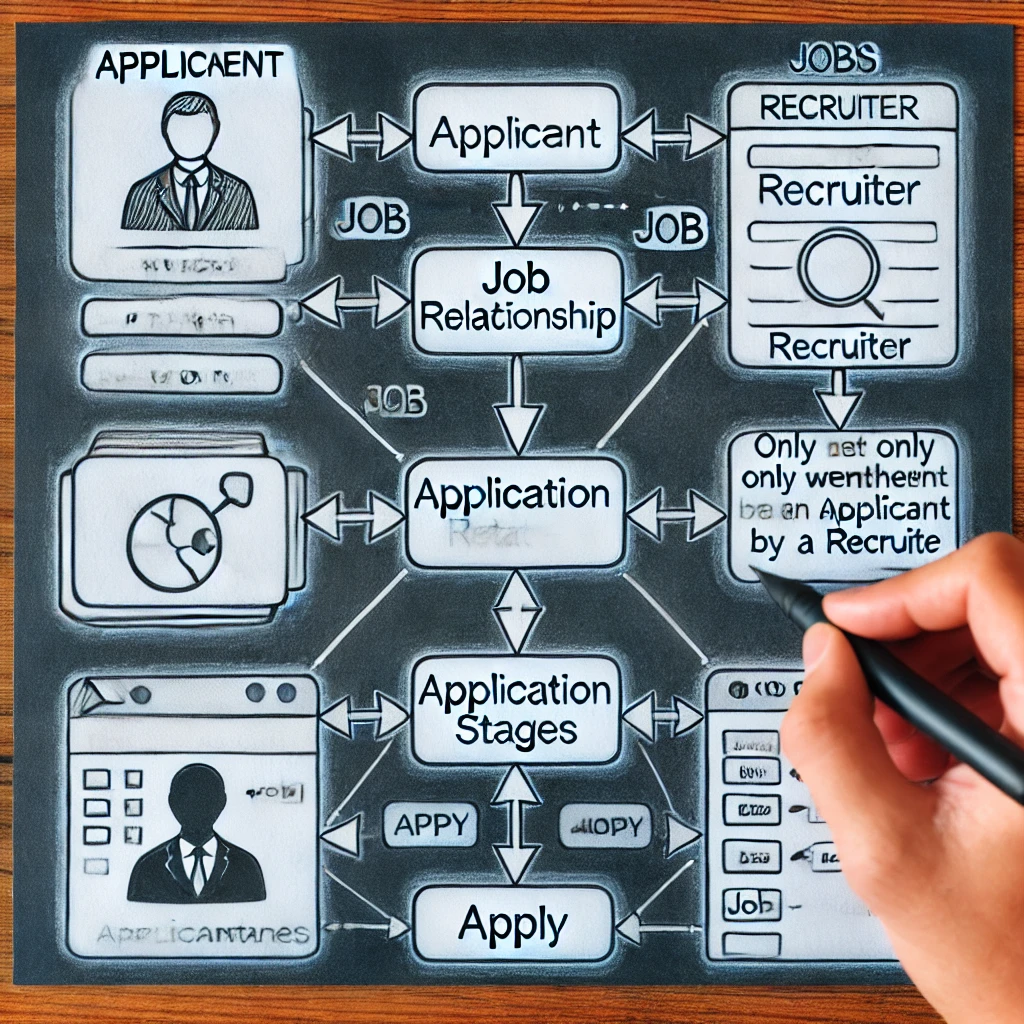
Een complex kenmerk of ternaire relatie selecteren in een ERD voor een werkwervingssysteem
Het ontwerpen van een georganiseerd en effectief -taakwervingssysteem vereist een inzicht in hoe de toepassing verbinding in een ERD te modelleren. Of het nu ApplicationStages moet vertegenwoordigen als een gecompliceerd kenmerk of als een zwak object is een cruciale keuze. De methode bootst beter na de werkelijke aanwervingsprocedures door te garanderen dat applicatiestadia alleen na de shortlisting verschijnen. Het juiste ontwerpbeslissing maken verbetert de databasesnelheid en garandeert het garanderen van schaalbaarheid en vraag eenvoud. Door de gegevenskwaliteit te vergroten en kandidaat -tracking te versnellen, helpt deze methodische techniek zowel recruiters als kandidaten.