Liam Lambert
1 lutego 2025
Wybór złożonego atrybutu lub relacji trójskładnikowej w ERD dla systemu rekrutacji pracy
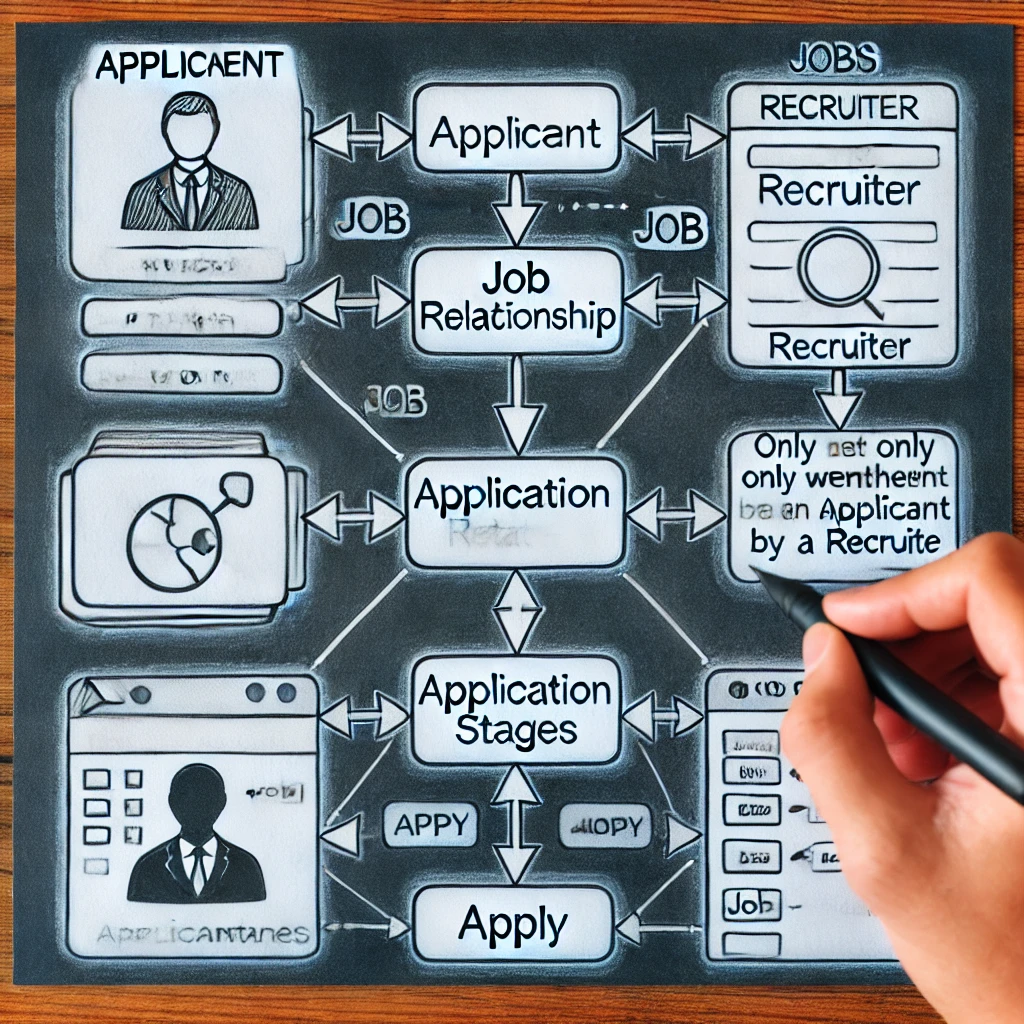
Projektowanie zorganizowanego i skutecznego systemu rekrutacji pracy wymaga zrozumienia, w jaki sposób modelować połączenie zastosowanie w ERD. Niezależnie od tego, czy reprezentować STAGES APPLIKACJI jako skomplikowany atrybut, czy jako słaby obiekt, jest kluczowym wyborem. Metoda bardziej naśladuje faktyczne procedury zatrudniania, gwarantując, że etapy aplikacji pojawiają się tylko po krótkiej liście. Podejmowanie prawidłowej decyzji projektowej poprawia szybkość bazy danych, jednocześnie gwarantując skalowalność i prostotę zapytania. Zwiększając jakość danych i przyspieszając śledzenie kandydatów, ta metodyczna technika pomaga zarówno rekruterom, jak i kandydatom.