Liam Lambert
1 fevereiro 2025
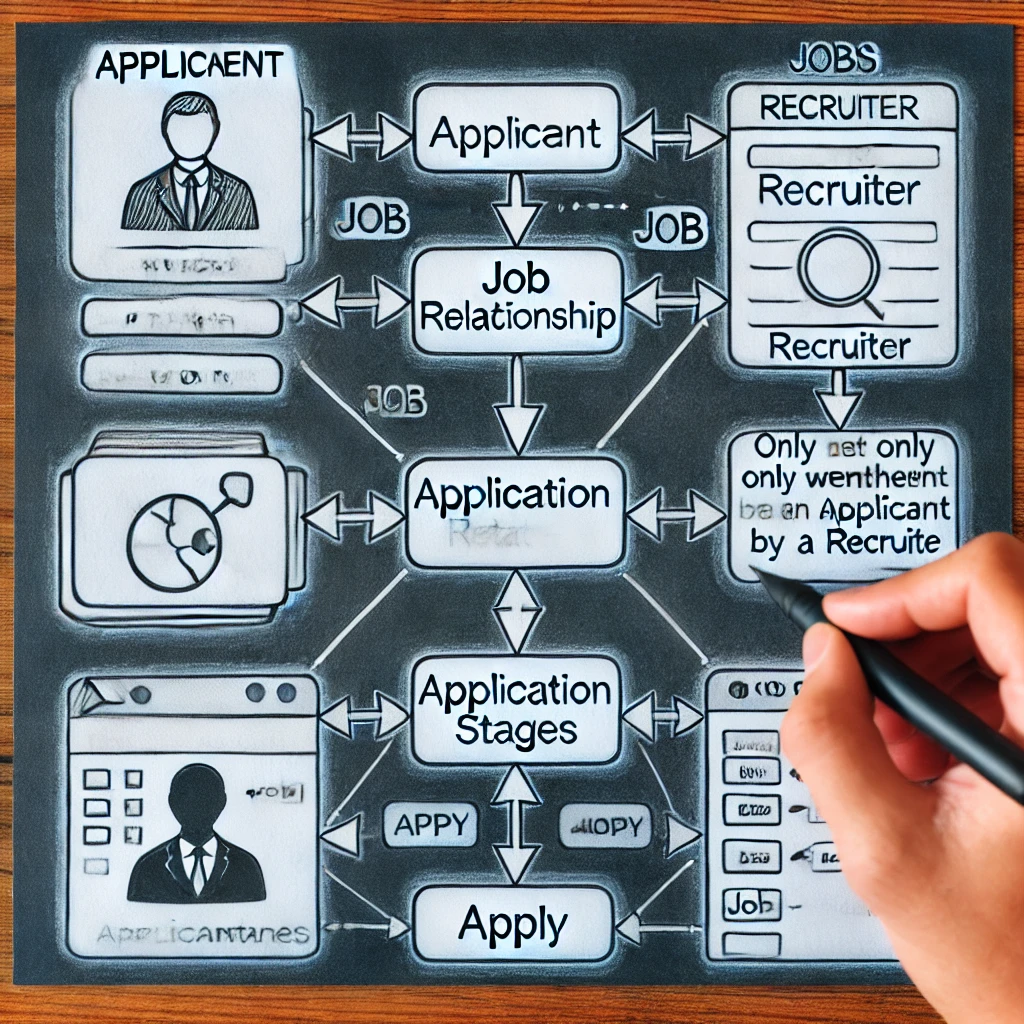
Selecionando um atributo complexo ou relacionamento ternário em um ERD para um sistema de recrutamento de empregos
A projeção de um sistema de recrutamento de empregos organizado e eficaz requer uma compreensão de como modelar a conexão aplicar em um ERD. Se deve representar ApplicationStages como um atributo complicado ou como um objeto fraco é uma escolha crucial. O método imita mais de perto os procedimentos de contratação reais, garantindo que os estágios do aplicativo apareçam apenas após a lista de curtas. A tomada da decisão correta do projeto melhora a velocidade do banco de dados, garantindo escalabilidade e simplicidade de consultas. Ao aumentar a qualidade dos dados e acelerar o rastreamento de candidatos, essa técnica metódica ajuda os recrutadores e os candidatos.