Liam Lambert
1 февраля 2025
Выбор сложного атрибута или тройных отношений в ERD для системы найма работы
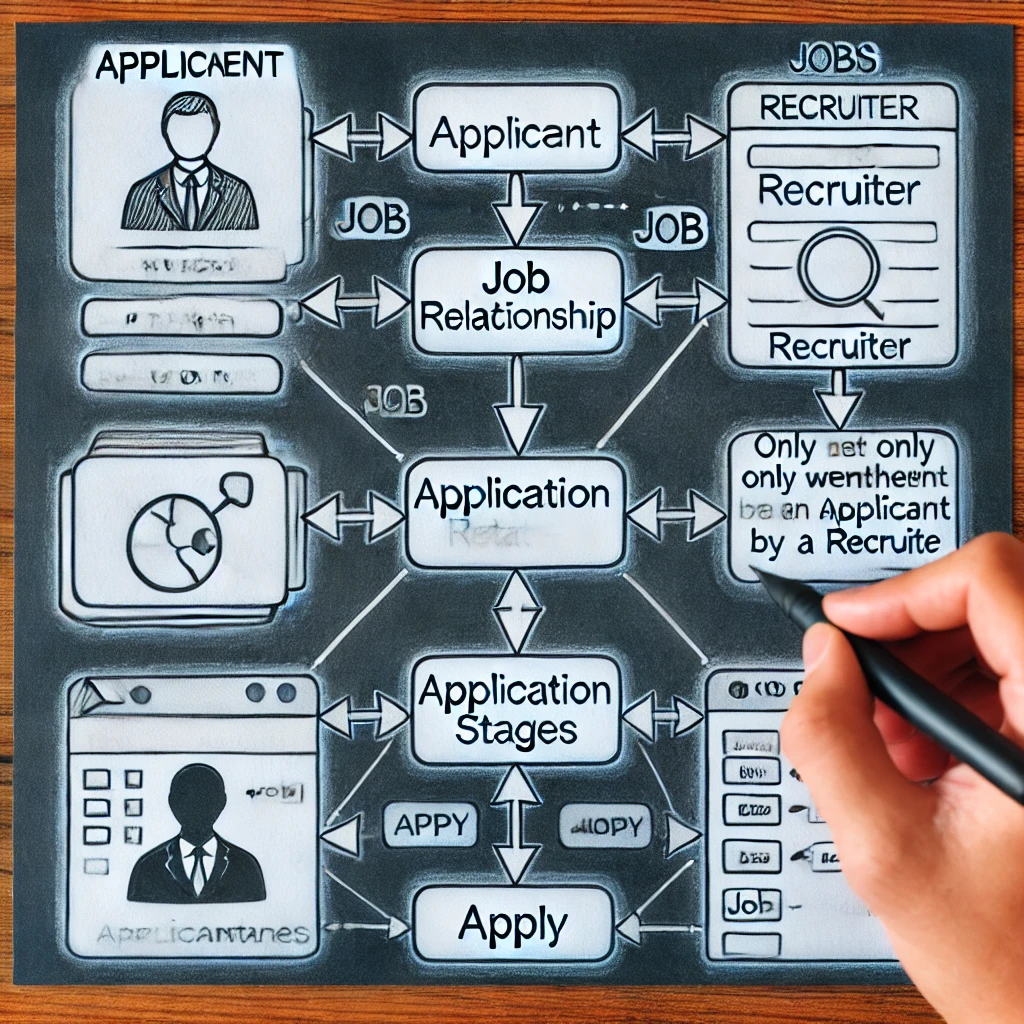
Проектирование организованной и эффективной системы рекрутинга задачи требует понимания того, как моделировать соединение применять в ERD. Представляю ли ApplectStages сложный атрибут или как слабый объект, является важным выбором. Метод более внимательно имитирует фактические процедуры найма, гарантируя, что этапы приложения отображаются только после шорт -листа. Принятие правильного дизайнерского решения улучшает скорость базы данных, гарантируя масштабируемость и простоту запроса. Повышая качество данных и ускоряя отслеживание кандидатов, этот методический метод помогает как рекрутерам, так и кандидатам.