Liam Lambert
1 februára 2025
Výber komplexného atribútu alebo ternárneho vzťahu v ERD pre systém náboru pracovných miest
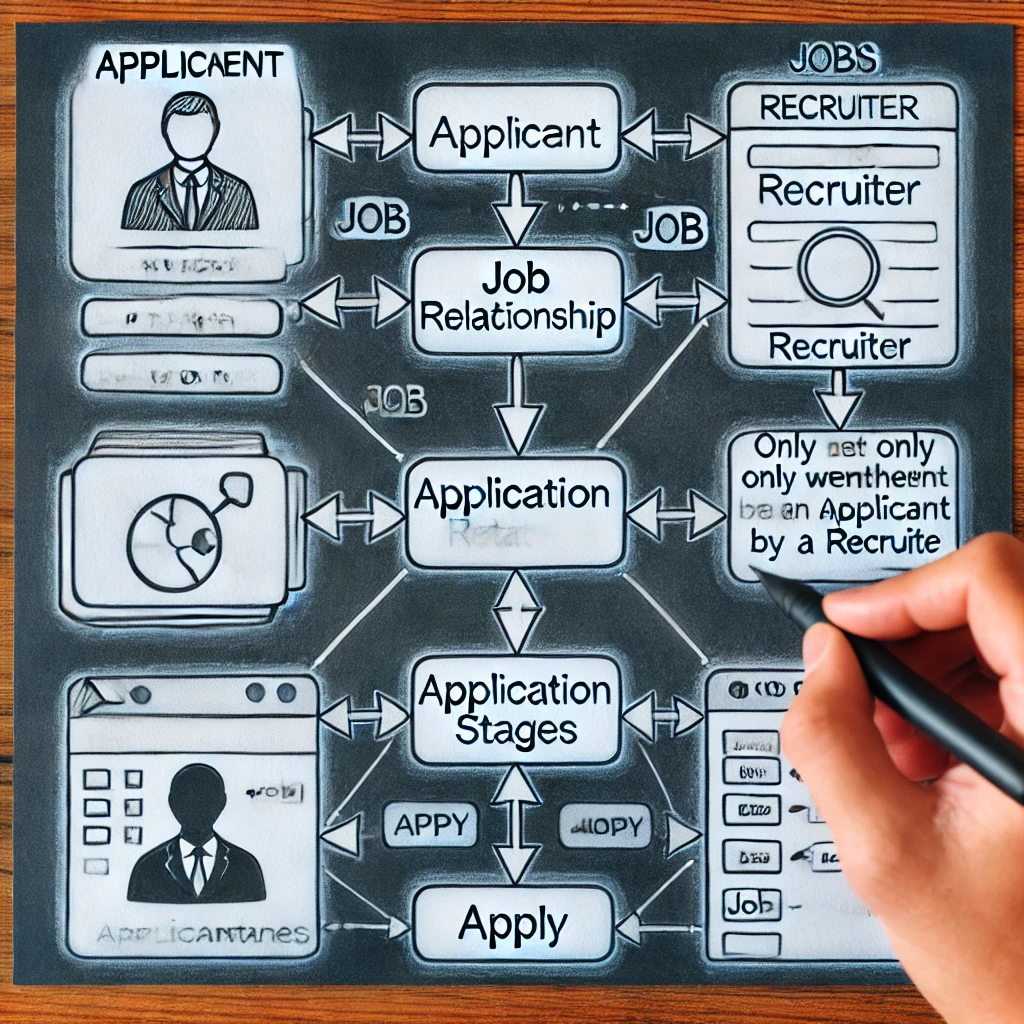
Navrhovanie organizovaného a efektívneho systému náboru pracovných miest si vyžaduje pochopenie toho, ako modelovať pripojenie aplikovať v ERD. Či je rozhodujúcou voľbou ApplicationStages ako komplikovaný atribút alebo ako slabý objekt. Táto metóda podrobnejšie napodobňuje skutočné postupy prijímania do zamestnania tým, že zaručuje, že etapy aplikácie sa zobrazujú iba po užšom zozname. Správne rozhodnutie o návrhu zlepšuje rýchlosť databázy a zároveň zaručuje škálovateľnosť a jednoduchosť dotazu. Zvýšením kvality údajov a urýchlením sledovania kandidátov táto metodická technika pomáha náborových pracovníkov aj kandidátov.