Liam Lambert
1 februari 2025
Att välja ett komplext attribut eller ett ternärt förhållande i en ERD för ett jobbrekryteringssystem
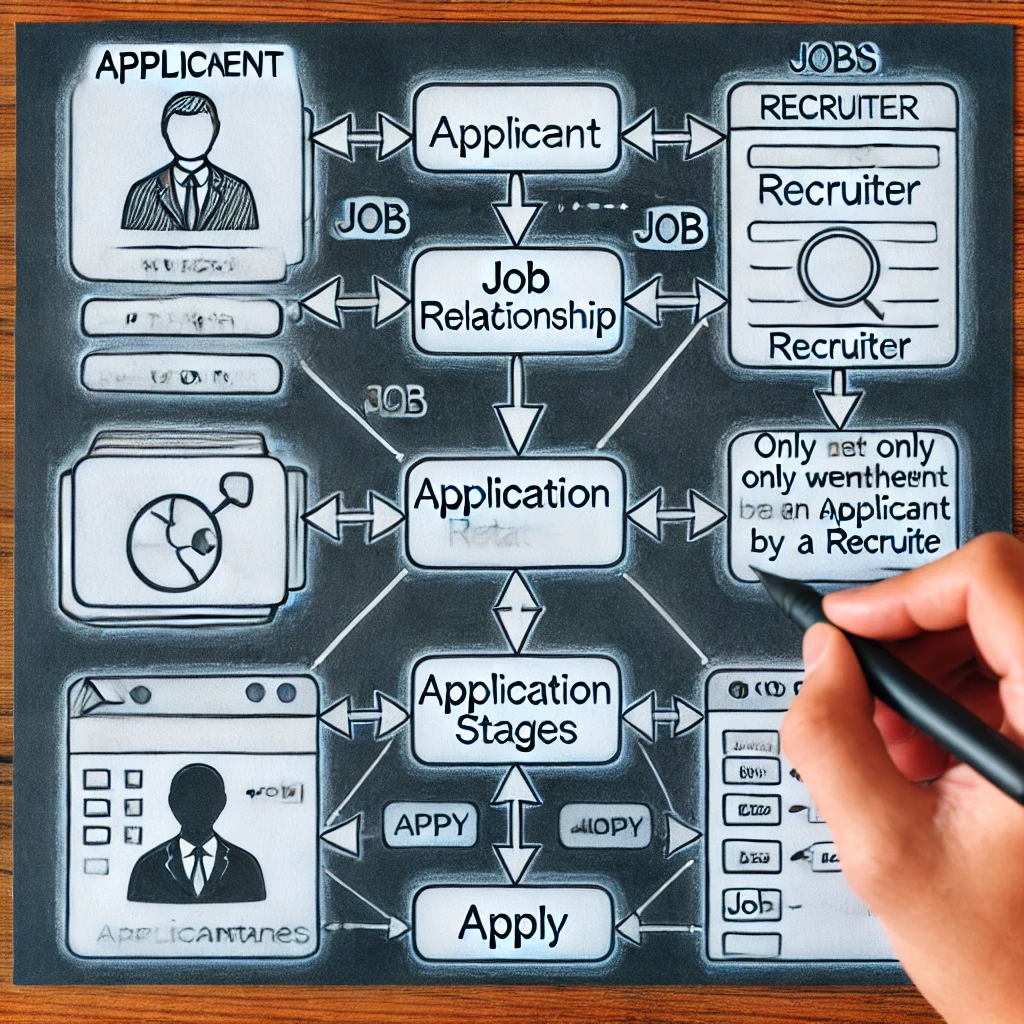
Att utforma ett organiserat och effektivt jobbrekryteringssystem kräver en förståelse för hur man modellerar Apply -anslutningen i en ERD. Huruvida man ska representera ApplicationStage som ett komplicerat attribut eller som ett svagt objekt är ett avgörande val. Metoden efterliknar närmare faktiska anställningsförfaranden genom att garantera att applikationssteg endast dyker upp efter kortlista. Att fatta rätt designbeslut förbättrar databashastigheten samtidigt som man garanterar skalbarhet och en enkelhets enkelhet. Genom att öka datakvaliteten och påskynda kandidatspårningen hjälper denna metodiska teknik både rekryterare och kandidater.